

Supervised Machine Learning

 by bista-admin
by bista-admin- Apr 26, 2017
- 0
- Category: Business Intelligence, Machine Learning
Introduction
Machine Learning is a core subarea of ‘’Artificial Intelligence’’, which learns from an existing model, results, and observations. We can define it as a subfield of computer science that gives computers the ability to learn without being explicitly programmed.”
More in detail, machine learning is a set of techniques or algorithms which are used to program computers and make decisions automatically and more accurately.
How does “Machine Learning” make decisions?
It makes decisions by analyzing (or learning) patterns in past data and applying them to future data. There can be different forms of decisions such as predictions of customer behavior, financial decisions – stock price prediction, fraud detection, and much more.
Types of Machine Learning Algorithm:
Majorly there are three different types of machine learning algorithms:
- Supervised Machine Learning
- Un-Supervised Machine Learning
- Reinforcement Machine Learning
Supervised Machine Learning(SML)
The majority of practical machine learning uses supervised learning. In Supervised machine learning algorithms, we have both input(X) and output(Y) variables and the algorithm generates a function that predicts the output(Y) based on given input(X) variables. It is called ‘supervised’ because the algorithm learns in a supervised manner. This learning process iterates over the training data until the model achieves an expected or closest to the expected result.
Supervised learning problems can be further divided into two parts:
- Regression: A supervised problem is said to be a regression problem when the output variable is a continuous value such as “weight”, “height” or “dollars.”
- Classification: It is said to be a classification problem when the output variable is a discrete (or category) such as “male” and “female” or “disease” and “no disease.”
Application of Supervised Learning:
Classification Method – Decision Tree
Here, I am using the “German Credit” data for the sake of understanding, having 1000 number of records and 21 columns, let’s see what information we can get from this data using predictive analytic techniques.

Now, we have an overview of the credit data and a basic idea about the credit data.
Let’s start working with a supervised learning method – “Decision Tree” (DT) and for that, I am going to use the R tool. These are the classification models that partition data into subsets based on categories of input variables.

Initially, we decide on the target variable i.e. Creditability, and later looking the impact of other variables on the target variable and we can treat them accordingly.
Below, is the DT plot from which it can easily identify the different levels and nodes of DT. The classification criteria for the different levels are calculated with the help of entropy.
Decision – Tree:
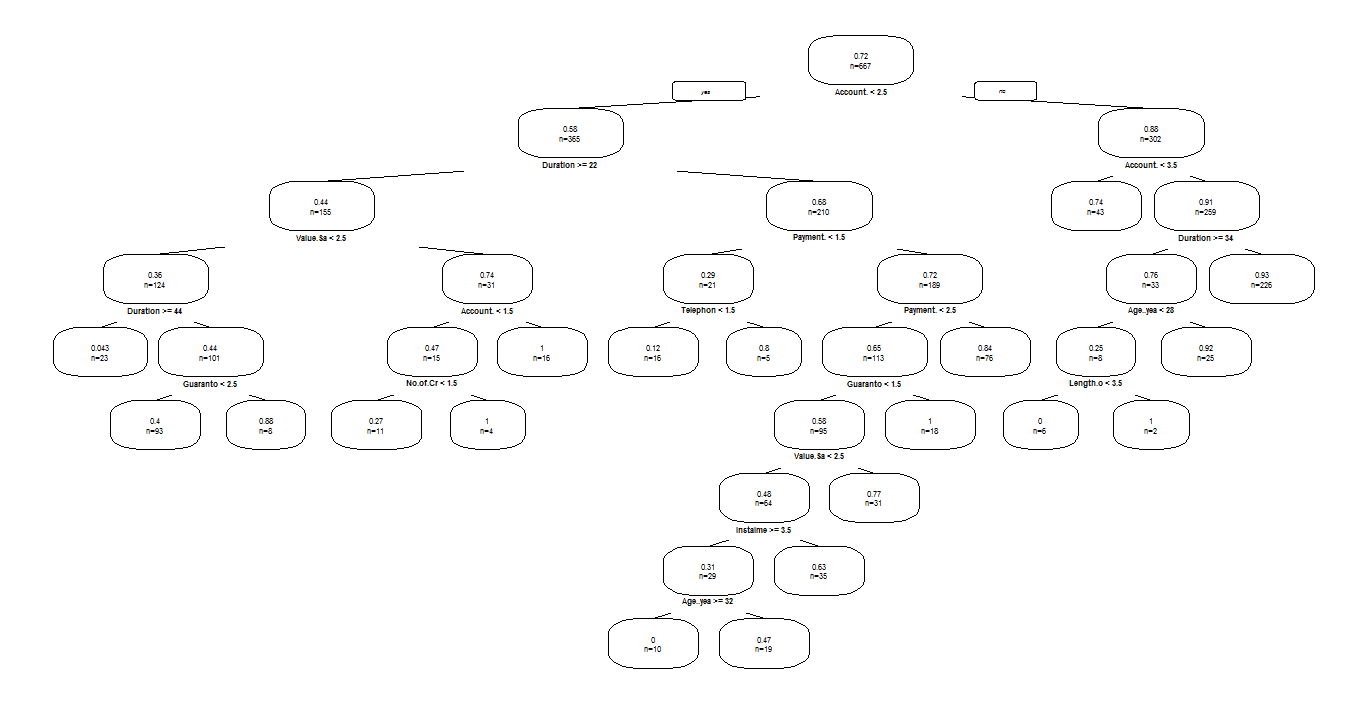
The multi-layered decision tree above clearly shows the distribution of different levels based on entropy value. The decision tree gives us the decision level idea of the data where we can take complex business decisions and know the profitable customers as well.
Some popular examples of supervised machine learning algorithms are:
- Linear regression for regression problems.
- Random forest for classification and regression problems.
- Support vector machines for classification problems.
What Else Can We Do with Supervised Machine Learning?
- Speech Recognition
- Face detection
- Fraudulent activities detection
- Social network analysis to define groups of friends
Conclusion:
Supervised learning is just getting good with every coming day. Machine learning can make the impossible things possible with a higher accuracy rate.
In short, Machine learning is considered as one of the most trending technological methodologies for better innovations.
For a demo on Supervised Machine Learning contact us or email us at sales@bistasolutions.com.


