Benefits Of Big Data On Cloud Computing

Big Data “Evolution”
“You can have data without information, but you cannot have information without data.” – Daniel Keys Moran
The above quote defines the importance of data. Ignoring the importance of big data can lead to be a very costly mistake for any kind of business in today’s world. If data is that important then using effective analytics or big data tools to unlock the hidden power of data becomes imperative. Here we will discuss the benefits of using cloud computing for big data. If you have followed our earlier blogs, we have discussed at length the value of big data and here we will explore it even further.
Today, every organization, government, IT firm and political party considers data as a new and extremely useful currency. They willingly invest resources to unlock insights from collected data in their respective fields which can be profitable if it is adequately mined, stored and analyzed.
The early stages of using big data were mostly based around storing the data and applying some basic analytics modules. Now, as the practice has evolved, we have adopted more advanced methods of modeling, transforming, and extracting on a much larger scale. The field of big data now has the capacity for a globalized infrastructure.
Internet and social media giants such as Google and Facebook were the pioneers of big data when they began uncovering, collecting and analyzing information collected by their users. Back then companies and researchers entered worked with externally sourced data, which was basically drawn from the “internet” or “public data sources”. The term “big data” wasn’t coined until 2010 approximately when they realized the power, need and importance of this information. Given the scope of information, the term “big data” come into the picture. And with that, the arrival of newly developed technologies and processes to help companies to turn the data into insight and profit.
Big Data “Establishment”
The term Big Data is being rapidly used almost everywhere across the planet – online and offline. Before that, information stored on your servers or computers was only sorted and filed. But today, all data becomes big data no matter where you have stored it or in which format.
How big is Big-Data?
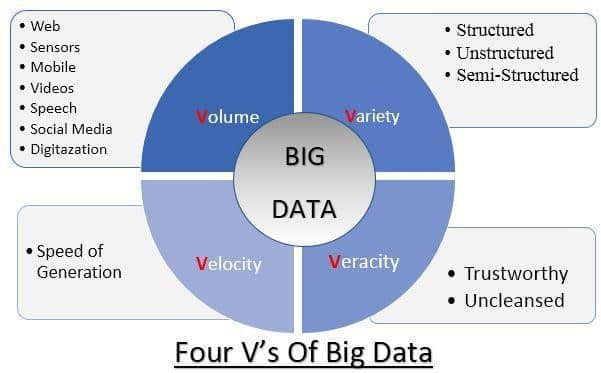
Essentially, all the digital data available and combined is “Big Data”. Many researchers agree that Big Data – as such – cannot be handled using normal spreadsheets and any regular tools of database management. Processing of big data requires specialized analytical tools or infrastructures like “Hadoop” database or NoSQL. These tools are able to handle a larger volume of information and in various formats, so that all the data can be handled in a single operation. “Big data” processing can be basically broken down into four big Vs which are Velocity, Variety, Veracity, and Volume.
Let’s dig in to “big data and a role of analytics” a bit further. The figure below helps to visualize and understand the four big V’s.
Why should we have big data on the cloud?
There are several reasons for having a big data on cloud. Some of them are discussed below:
 Instant infrastructure
Instant infrastructure
One of the key benefits of a cloud-based approach to big data analytics is the ability to establish big data infrastructure as quickly as possible with a scalable environment. A big data cloud service provides the infrastructure that companies would otherwise have to build up themselves from scratch.
Big data offers all analytics needs in a single roof. It is important to note that cloud-based big data analytics success is dependent on many key factors. Most significant of these is the quality and reliability of the solution provider. The vendor must combine robust, extensive expertise in both the big data and cloud computing sectors.
Cutting costs with big data in the cloud
This offers major financial advantages to participating companies, but how? Performing big data analytics in the house requires companies to attain and maintain big data centres, and maintain the big data centres is more about, that budget can be used in other companies’ expansion plans and policies.
Shifting the big data analytics on the cloud, allows firms to cut costs in terms of purchasing equipment, cooling machines and ensuring security, while also allowing them to keep the most sensitive data on-premise and have the full control on it.
Fast Time to Value
A modern data-management platform brings together master data management and big data analytics capabilities in the cloud so that business can create data-driven applications using the reliable data with relevant insights. The principal advantage of this unified cloud platform is faster time-to-value, keeping up with the pace of business. Whenever there is a need for a new, data-driven decision management application, you can create one in the cloud quickly. There is no need to set up infrastructure (hardware, operating systems, databases, application servers, analytics), create new integrations, or define data models or data uploads. In the cloud, everything is already set up and available.
Conclusion:
Cloud-based data management as a service helps organizations to blend master data and big data across all domains. This union of data, operations, and analytics, in a closed-loop, provides an unprecedented level of agility, collaboration, and responsiveness. All made possible by cloud technologies.
There are many benefits keeping the big data on cloud. For more insights on big data analytics and cloud computing, you can get in touch with us through sales@bistasolutions.com .